ML prediction models
In the BlueHealthPass project we use machine learning to estimate specific conditions’ levels based on health and activity data collected from wearable activity trackers.
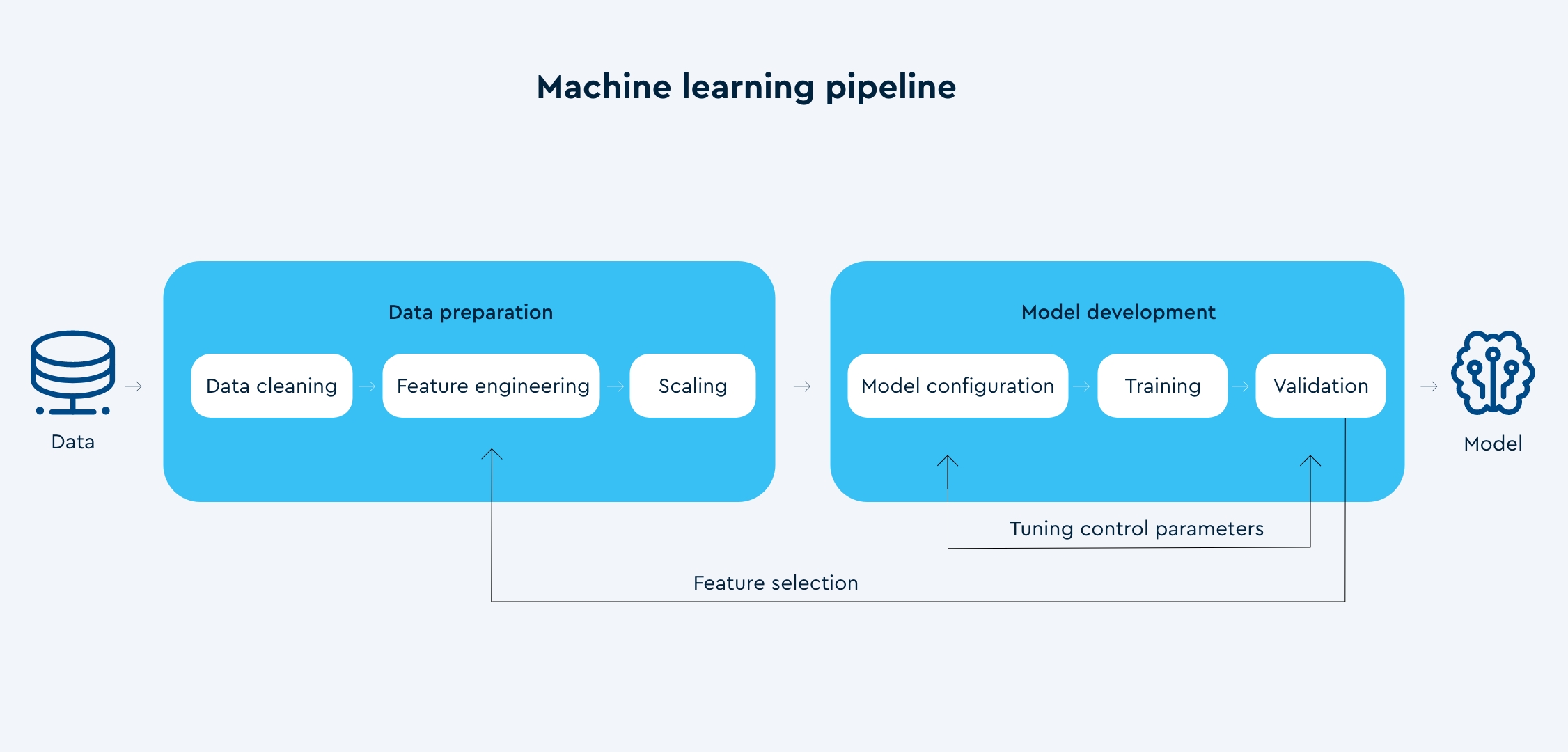
The process of creating machine learning models involves the following steps:
– Machine learning relies on large amounts of data, and the collected data needs to be cleaned of invalid and missing data points to ensure high quality input to the machine learning algorithm.
– Feature engineering is then be performed on the cleaned dataset, in order to extract high level features that usually are critical for making accurate predictions from the input data.
– Scaling is an important part of the data preparation process, where all the input features are normalized to a fixed range of values.
– After the data is preprocessed, it is used to train a machine learning model. The choice of machine learning algorithm is among other things based on the amount of data, what type of input features we have, and whether we are predicting a category (classification, for example fatigue level) or a continuous variable (regression, for example fatigue score). We also need to specify certain configuration parameters that define the model and the training process, which will differ based on what algorithm we choose to use.
– When the training is done, we validate the model by testing it on unseen data. To improve the performance of a model, we can reiterate the process by selecting different input features and tuning the configuration parameters of the machine learning algorithm.